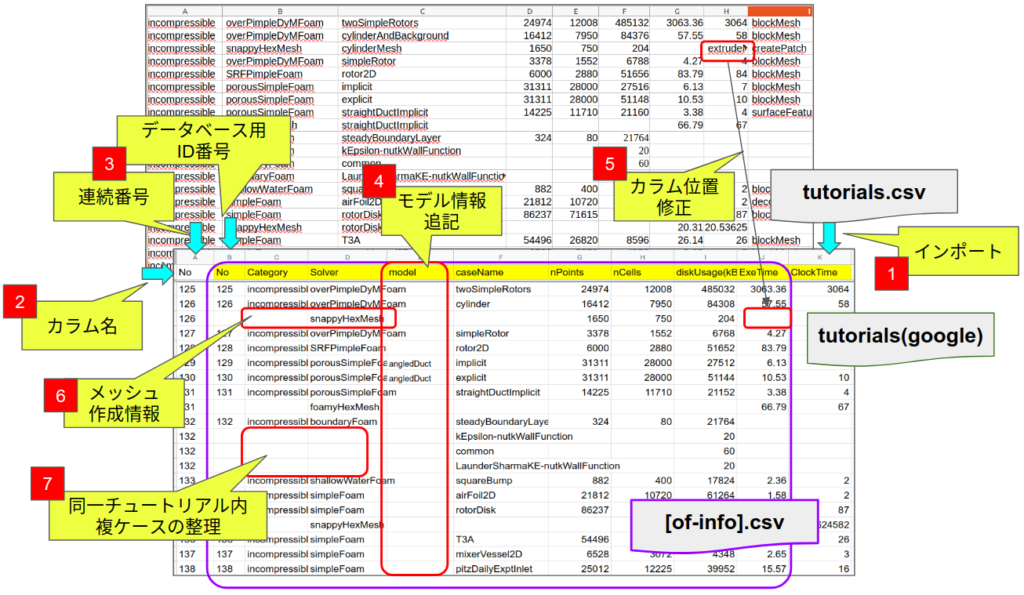
インポート![]() した後で、
した後で、![]() データベース用のID番号を指定するカラムと、
データベース用のID番号を指定するカラムと、![]() モデル情報を追記するためのカラムを追加している。
モデル情報を追記するためのカラムを追加している。
カラムの並びは、チュートリアルのフォルダー構成そのままに、カテゴリー名、ソルバー名、ケース名 に引き続き、メッシュ節点数、要素数、使用ディスクスペース、計算時間(exe)、計算時間(calk)、使用ユーティリティ、となっているが、必ずしも列が揃っているわけではない。
列が揃わない原因は、clockTimeを取得できなかった場合で、かつログファイル情報も取得できていないケース![]() が該当し、まだ十分に検証できていないが、プログラム改良は予定している。
が該当し、まだ十分に検証できていないが、プログラム改良は予定している。
列が揃わない事以外にも大きな問題が3つあって、これらも今の所、手作業でデータを修正している。
- snappyHexMeshなどメッシュ作成情報を追記した行

- モデル情報
 が未取得
が未取得 - チュートリアルケース名と解析フォルダが一致しないケース



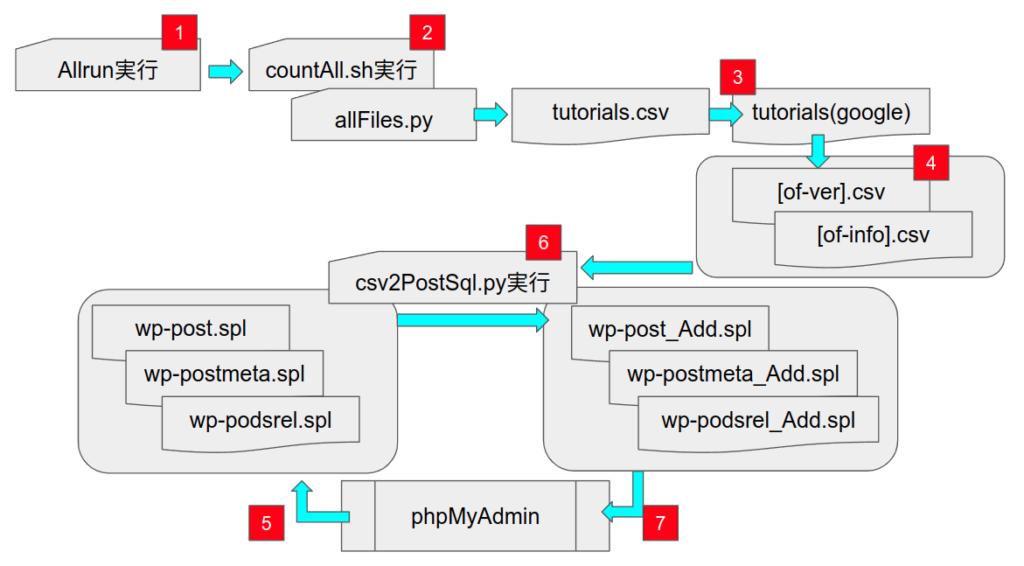
googleドキュメントの tutorialsシートでの作業が終了したら、図2.の紫色の枠で囲った部分をコピーして、データベース用のsplファイルへの変換元データとしてcsvファイルにエクスポートしている(図1.![]() )。
)。
また、併せて、当該データセットの付帯情報(OpenFOAMのヴァージョン、計算環境)を記したファイルも作成しておく。


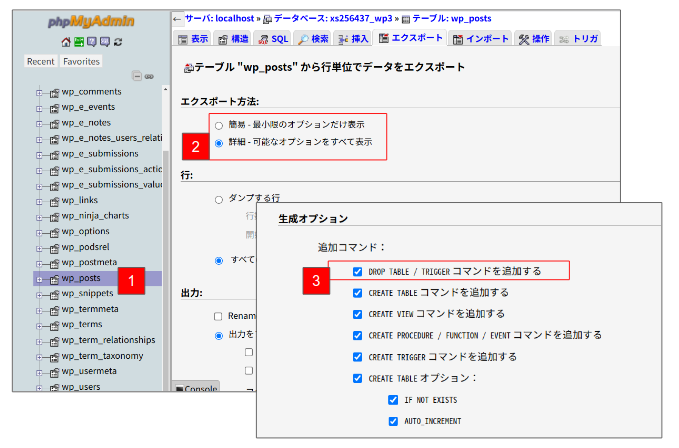
データベースを追加するには、最新のWordPressのデータベースをエクスポート(図1.![]() )して、これに追加分を加えたデータベースファイルをインポートする。WordPressのデータベースをエクスポートするには、phpMyAdminを使っており、対象データベースは以下の3つ,
)して、これに追加分を加えたデータベースファイルをインポートする。WordPressのデータベースをエクスポートするには、phpMyAdminを使っており、対象データベースは以下の3つ,
- wp_posts
- wp_postmeta
- wp_podsrel
であるが、エクスポートオプションとして、1点デフォルト変更する箇所がある。
ピンバック: Allrunログデータ取得の完全自動化に向けて – E.Mogura's OpenFOAM®